
Yifu Diao
Software Engineer
Engineering
Building Microservices from Scratch
We’re Cardless. We help brands launch credit cards for their most important customers. A bit more on us and our first brand partner, the Cleveland Cavaliers NBA team, here.
Monolith vs. Microservices
Building a credit card company from the ground up is a hefty task! We started investigating requirements in March 2020. By then, we knew consistency, availability, security and compliance would be crucial to the success of our systems.
The first decision we faced was whether to build a monolith or microservices.
While monolith can be built with a simple infrastructure and offer unified logging and configuration, we knew we would soon hit bottlenecks.
Microservices, on the other hand, have been adopted by practically all of our peer tech companies. A few members of our team formerly worked at companies that decided to transition from monolith to microservices, investing significant time and resources into the transition.
We knew it would take several quarters to build the product, so starting with microservices was the clear choice to save us the migration down the line. Benefits include:
Decoupling — each service is free to choose its own technologies such as programming language and database.
Parallel development — each service can be developed and deployed independently, accelerating development speed and minimizing the blast radius if one deployment goes wrong.
Clarity of ownership — ownership of each service is well-defined, as is the set of things owned by each individual and team — avoiding the all-too-common situation of fuzzy ownership of a large shared monolith codebase.
The latest and greatest — building microservices from scratch means we can leverage the latest and best technologies such as gRPC, Kubernetes and Envoy.
gRPC and Proto Registry
RPC vs REST API
With a microservices architecture, we need to have an API framework for inter service communications. Compared to REST API, RPC offers several benefits:
Clear interface definition for input, output and error handling.
Automatically generated data access classes that are easier to use programmatically.
Compact, schematized binary formats used in RPC offer significant efficiencies over JSON data payloads.
So, we chose RPC.
gRPC vs Thrift
We then had to decide between the two popular RPC frameworks: gRPC and Apache Thrift. Our team had experience with Thrift, but after some investigation we found gRPC has some clear advantages:
Well maintained. gRPC is backed by Google. While Thrift was open sourced by Facebook, they have since forked with fbthrift and stopped development on Apache Thrift.
Better documentation. gRPC and Protocol Buffers has much better documentation than Apache Thrift.
Officially supported clients. gRPC has official support for all major languages, while Apache thrift only offers community implementation
Built with HTTP/2. Enables multiplexing HTTP/2 transport and bi-directional streaming.
Once again, we had a clear frontrunner.
Proto Registry
Once we had chosen to use gRPC, how did we organize the proto files? Each of our gRPC services had their own repository, and initially we had each service defining its proto file in the same repository.
For service A to call service B, we needed to manually copy the proto file of service B into service A to generate the client code.
We quickly realized that this approach wouldn’t scale and is also prone to error. So we built a proto registry that has all the proto files in one repository.
The proto registry publishes generated code as Java packages to Github Packages whenever a new change is merged to the master branch. As a result, whenever we need to make proto changes, we make them in the proto registry repository, merge it and upgrade the service to use the latest proto Java library.
This approach has worked very well for us so far, and has had the added benefit of enabling us to share some common proto files across services.
Microservices Infrastructure
Hosting: ECS vs Kubernetes -> Amazon EKS
The first infrastructure decision we faced was where to host the microservices.
We first experimented with Amazon ECS, and found it very easy to onboard. We then evaluated Kubernetes — we liked that it doesn’t require vendor lock in and has a much better ecosystem than Amazon ECS.
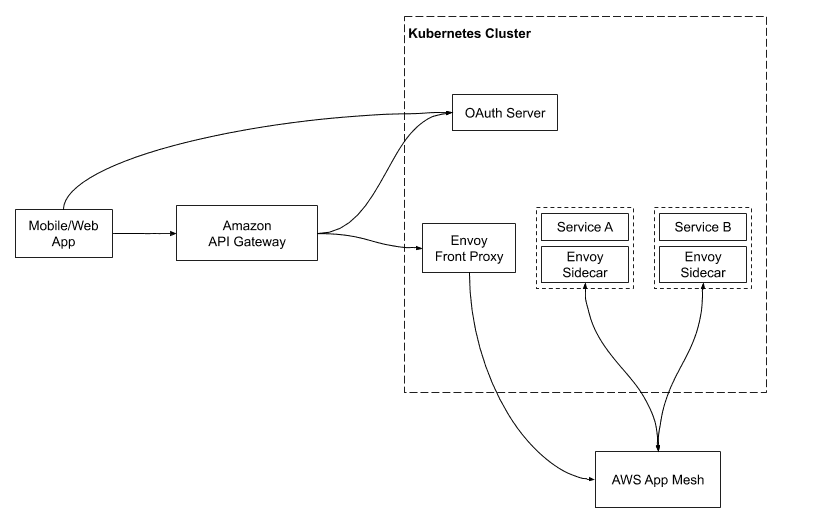
As a result, we decided to build a Kubernetes cluster with Amazon EKS, a managed Kubernetes service.
We used EC2 instead of AWS Fargate since Kubernetes already offers the auto scaling feature provided by Fargate. We placed all the nodes in the private subnet so that only the Amazon API Gateway could access them. With the Kubernetes cluster up and running, we configured each microservice to have its own Kubernetes deployment and service.
Service Mesh: Envoy + AWS App Mesh
Now that our services were running in Kubernetes and serving gRPC requests, how did they talk to each other?
We were surprised to find that Kubernetes’s default load balancing doesn’t work out of the box with gRPC. This is because gRPC was built on HTTP/2, which breaks the standard connection-level load balancing, including what’s provided by Kubernetes (more in this Kubernetes blog post).
We found there were a few service mesh solutions that add gRPC load balancing to Kubernetes clusters, namely Envoy, Istio and Linkerd.
After some investigation, we decided to use Envoy, which is both popular and provided as a managed service in AWS App Mesh. We configured AWS App Mesh as a Kubernetes CRD, so that Envoy sidecars are automatically injected into Kubernetes pods.
Envoy as the Front Proxy
Once our services were talking to each other through gRPC, how would our mobile and web clients talk to our services?
Our first thought was to just use gRPC, however we also needed Amazon API Gateway for authentication and VeryGoodSecurity for tokenization, and neither of them supports gRPC.
We did some investigation and found both Envoy and gRPC Gateway could act as a front proxy to transcode JSON requests to gRPC. We decided to use Envoy, since we were already using it as a sidecar to our services. We deployed the front proxy to Kubernetes and used an internal Network Load Balancer (NLB) to, well, balance loads.
The following is a simplified version of our Envoy front proxy configuration, which connects to the Users service in our service mesh:
static_resources:
listeners:
- name: restlistener
address:
socket_address:
address: 0.0.0.0
port_value: 80
filter_chains:
- filters:
- name: envoy.http_connection_manager
config:
stat_prefix: grpc_json
codec_type: AUTO
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains:
- '*'
routes:
- match:
prefix: /users
route:
cluster: users-service
timeout:
seconds: 60
http_filters:
- name: envoy.grpc_json_transcoder
config:
match_incoming_request_route: true
proto_descriptor: /proto/endpoints.pb
services:
- cardless.proto.api.users.UsersService
convert_grpc_status: true
print_options:
add_whitespace: true
always_print_primitive_fields: true
always_print_enums_as_ints: false
preserve_proto_field_names: false
- name: envoy.router
clusters:
- name: users-service
connect_timeout: 1.25s
type: logical_dns
lb_policy: round_robin
dns_lookup_family: V4_ONLY
http2_protocol_options: {}
hosts:
- socket_address:
address: users.svc.local
port_value: 10001The eagle-eyed among you may have noticed the file /proto/endpoints.pb referenced in the front proxy configuration. This file contains the descriptor sets generated from our proto registry.
Each microservice will expose their APIs by adding a HTTP annotation like this:
import "google/api/annotations.proto";
service UsersService {
rpc GetUser (GetUserRequest) returns (GetUserResponse){
option (google.api.http) = {
post: "/users/get-user"
And then we generate the endpoints.pb in the proto registry with this command:
protoc \
--include_imports \
--include_source_info \
--proto_path=./googleapis \
--proto_path=./cardless/proto \
--descriptor_set_out=descriptors/endpoints.pb \
./cardless/proto/users/api/users.protoAmazon API Gateway and Authentication
Our Envoy front proxy could transcode JSON requests to gRPC, but we still needed an API gateway to handle authentication and CORS and act as the web application firewall.
For enhanced peace of mind, we think it’s particularly important to let the API gateway authenticate all requests, instead of relying on each microservice to do so.
With this requirement, we found Amazon API Gateway’s support for OAuth with JWT Authorizers very attractive. The JWT Authorizer validates the access token in the authorization header of each request, making sure all the requests that reach our Envoy front proxy have been authenticated.
For issuing access tokens, we evaluated Amazon Cognito and Auth0, but decided to implement our own OAuth server with Spring Security since auth is at the core of our system and neither Amazon Cognito nor Auth0 provides sufficient flexibility.The OAuth server issues access tokens and refresh tokens after users authenticate with username and password, it also handles 2FA and password reset.
Developer Experience
We adopted a microservices architecture to enable engineers to iterate fast, but microservices also came with some overhead. So what could we do to provide a good developer experience?
Engineering Design Template
After a high level design exercise, we had a rough idea which microservices needed to be built. We wrote an engineering design template that guides engineers to think about alternatives (internal and external), architecture, API, database schema, infrastructure choices and security when proposing a new microservice.
After the engineer finishes the design document, we have a design review meeting and reach a consensus before we start building.
Java as Our Default Backend Language
One of the guidelines in the engineering design template is to use Java as the backend language unless there are strong reasons not to. Java’s static typing, high performance and rich ecosystem makes it a great choice as a backend language. But those aren’t the only reasons we make this recommendation.
By having a single backend language, engineers can work on multiple services easily. It also simplifies our effort to maintain shared libraries and service bootstrap templates.
Testing and Monitoring
For new changes, our engineers use Bloom RPC to test the updated gRPC endpoint locally. After the change is merged into the master branch, our CircleCI pipeline automatically deploys the build to our staging environment. Then our engineers can test the change end-to-end with Postman using JSON requests. We also monitor exceptions in Sentry and metrics in Datadog before we manually deploy the change to production.
Results
The microservices architecture has allowed us to iterate fast while achieving high availability and scalability.
As a team with modest infrastructure experience, we’ve leveraged managed services provided by AWS when possible, and built our own infrastructure when necessary.
Fun Facts
We’ve built 9 microservices with 5 engineers.
Our engineers can bootstrap a new microservice and deploy it to Kubernetes in 30 minutes with our Java service template.
After a change is accepted, it can be deployed to the staging environment in 10 minutes.
We haven’t had any outages caused by microservices infrastructure.
We can easily scale a service by adding more Kubernetes pods to the service.
With our microservices infrastructure, we easily separated production and staging environments in 2 weeks.
Final Thoughts
Looking back, adopting Java monorepo could have saved us time for managing dependencies, logging and configurations. We will explore migrating to a moneo repo and write follow up blog posts to further discuss proto registry, authentication, metrics and monitoring in the future. We are launching our product soon — if you are excited about building microservices at Cardless, please take a look at our open positions!
Join our team
We're looking for curious, driven, entrepreneurs to help us build the future of credit cards and loyalty.
Yifu Diao
Software Engineer
Engineering
Building Microservices from Scratch
We’re Cardless. We help brands launch credit cards for their most important customers. A bit more on us and our first brand partner, the Cleveland Cavaliers NBA team, here.
Monolith vs. Microservices
Building a credit card company from the ground up is a hefty task! We started investigating requirements in March 2020. By then, we knew consistency, availability, security and compliance would be crucial to the success of our systems.
The first decision we faced was whether to build a monolith or microservices.
While monolith can be built with a simple infrastructure and offer unified logging and configuration, we knew we would soon hit bottlenecks.
Microservices, on the other hand, have been adopted by practically all of our peer tech companies. A few members of our team formerly worked at companies that decided to transition from monolith to microservices, investing significant time and resources into the transition.
We knew it would take several quarters to build the product, so starting with microservices was the clear choice to save us the migration down the line. Benefits include:
Decoupling — each service is free to choose its own technologies such as programming language and database.
Parallel development — each service can be developed and deployed independently, accelerating development speed and minimizing the blast radius if one deployment goes wrong.
Clarity of ownership — ownership of each service is well-defined, as is the set of things owned by each individual and team — avoiding the all-too-common situation of fuzzy ownership of a large shared monolith codebase.
The latest and greatest — building microservices from scratch means we can leverage the latest and best technologies such as gRPC, Kubernetes and Envoy.
gRPC and Proto Registry
RPC vs REST API
With a microservices architecture, we need to have an API framework for inter service communications. Compared to REST API, RPC offers several benefits:
Clear interface definition for input, output and error handling.
Automatically generated data access classes that are easier to use programmatically.
Compact, schematized binary formats used in RPC offer significant efficiencies over JSON data payloads.
So, we chose RPC.
gRPC vs Thrift
We then had to decide between the two popular RPC frameworks: gRPC and Apache Thrift. Our team had experience with Thrift, but after some investigation we found gRPC has some clear advantages:
Well maintained. gRPC is backed by Google. While Thrift was open sourced by Facebook, they have since forked with fbthrift and stopped development on Apache Thrift.
Better documentation. gRPC and Protocol Buffers has much better documentation than Apache Thrift.
Officially supported clients. gRPC has official support for all major languages, while Apache thrift only offers community implementation
Built with HTTP/2. Enables multiplexing HTTP/2 transport and bi-directional streaming.
Once again, we had a clear frontrunner.
Proto Registry
Once we had chosen to use gRPC, how did we organize the proto files? Each of our gRPC services had their own repository, and initially we had each service defining its proto file in the same repository.
For service A to call service B, we needed to manually copy the proto file of service B into service A to generate the client code.
We quickly realized that this approach wouldn’t scale and is also prone to error. So we built a proto registry that has all the proto files in one repository.
The proto registry publishes generated code as Java packages to Github Packages whenever a new change is merged to the master branch. As a result, whenever we need to make proto changes, we make them in the proto registry repository, merge it and upgrade the service to use the latest proto Java library.
This approach has worked very well for us so far, and has had the added benefit of enabling us to share some common proto files across services.
Microservices Infrastructure
Hosting: ECS vs Kubernetes -> Amazon EKS
The first infrastructure decision we faced was where to host the microservices.
We first experimented with Amazon ECS, and found it very easy to onboard. We then evaluated Kubernetes — we liked that it doesn’t require vendor lock in and has a much better ecosystem than Amazon ECS.
As a result, we decided to build a Kubernetes cluster with Amazon EKS, a managed Kubernetes service.
We used EC2 instead of AWS Fargate since Kubernetes already offers the auto scaling feature provided by Fargate. We placed all the nodes in the private subnet so that only the Amazon API Gateway could access them. With the Kubernetes cluster up and running, we configured each microservice to have its own Kubernetes deployment and service.
Service Mesh: Envoy + AWS App Mesh
Now that our services were running in Kubernetes and serving gRPC requests, how did they talk to each other?
We were surprised to find that Kubernetes’s default load balancing doesn’t work out of the box with gRPC. This is because gRPC was built on HTTP/2, which breaks the standard connection-level load balancing, including what’s provided by Kubernetes (more in this Kubernetes blog post).
We found there were a few service mesh solutions that add gRPC load balancing to Kubernetes clusters, namely Envoy, Istio and Linkerd.
After some investigation, we decided to use Envoy, which is both popular and provided as a managed service in AWS App Mesh. We configured AWS App Mesh as a Kubernetes CRD, so that Envoy sidecars are automatically injected into Kubernetes pods.
Envoy as the Front Proxy
Once our services were talking to each other through gRPC, how would our mobile and web clients talk to our services?
Our first thought was to just use gRPC, however we also needed Amazon API Gateway for authentication and VeryGoodSecurity for tokenization, and neither of them supports gRPC.
We did some investigation and found both Envoy and gRPC Gateway could act as a front proxy to transcode JSON requests to gRPC. We decided to use Envoy, since we were already using it as a sidecar to our services. We deployed the front proxy to Kubernetes and used an internal Network Load Balancer (NLB) to, well, balance loads.
The following is a simplified version of our Envoy front proxy configuration, which connects to the Users service in our service mesh:
static_resources:
listeners:
- name: restlistener
address:
socket_address:
address: 0.0.0.0
port_value: 80
filter_chains:
- filters:
- name: envoy.http_connection_manager
config:
stat_prefix: grpc_json
codec_type: AUTO
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains:
- '*'
routes:
- match:
prefix: /users
route:
cluster: users-service
timeout:
seconds: 60
http_filters:
- name: envoy.grpc_json_transcoder
config:
match_incoming_request_route: true
proto_descriptor: /proto/endpoints.pb
services:
- cardless.proto.api.users.UsersService
convert_grpc_status: true
print_options:
add_whitespace: true
always_print_primitive_fields: true
always_print_enums_as_ints: false
preserve_proto_field_names: false
- name: envoy.router
clusters:
- name: users-service
connect_timeout: 1.25s
type: logical_dns
lb_policy: round_robin
dns_lookup_family: V4_ONLY
http2_protocol_options: {}
hosts:
- socket_address:
address: users.svc.local
port_value: 10001The eagle-eyed among you may have noticed the file /proto/endpoints.pb referenced in the front proxy configuration. This file contains the descriptor sets generated from our proto registry.
Each microservice will expose their APIs by adding a HTTP annotation like this:
import "google/api/annotations.proto";
service UsersService {
rpc GetUser (GetUserRequest) returns (GetUserResponse){
option (google.api.http) = {
post: "/users/get-user"
And then we generate the endpoints.pb in the proto registry with this command:
protoc \
--include_imports \
--include_source_info \
--proto_path=./googleapis \
--proto_path=./cardless/proto \
--descriptor_set_out=descriptors/endpoints.pb \
./cardless/proto/users/api/users.protoAmazon API Gateway and Authentication
Our Envoy front proxy could transcode JSON requests to gRPC, but we still needed an API gateway to handle authentication and CORS and act as the web application firewall.
For enhanced peace of mind, we think it’s particularly important to let the API gateway authenticate all requests, instead of relying on each microservice to do so.
With this requirement, we found Amazon API Gateway’s support for OAuth with JWT Authorizers very attractive. The JWT Authorizer validates the access token in the authorization header of each request, making sure all the requests that reach our Envoy front proxy have been authenticated.
For issuing access tokens, we evaluated Amazon Cognito and Auth0, but decided to implement our own OAuth server with Spring Security since auth is at the core of our system and neither Amazon Cognito nor Auth0 provides sufficient flexibility.The OAuth server issues access tokens and refresh tokens after users authenticate with username and password, it also handles 2FA and password reset.
Developer Experience
We adopted a microservices architecture to enable engineers to iterate fast, but microservices also came with some overhead. So what could we do to provide a good developer experience?
Engineering Design Template
After a high level design exercise, we had a rough idea which microservices needed to be built. We wrote an engineering design template that guides engineers to think about alternatives (internal and external), architecture, API, database schema, infrastructure choices and security when proposing a new microservice.
After the engineer finishes the design document, we have a design review meeting and reach a consensus before we start building.
Java as Our Default Backend Language
One of the guidelines in the engineering design template is to use Java as the backend language unless there are strong reasons not to. Java’s static typing, high performance and rich ecosystem makes it a great choice as a backend language. But those aren’t the only reasons we make this recommendation.
By having a single backend language, engineers can work on multiple services easily. It also simplifies our effort to maintain shared libraries and service bootstrap templates.
Testing and Monitoring
For new changes, our engineers use Bloom RPC to test the updated gRPC endpoint locally. After the change is merged into the master branch, our CircleCI pipeline automatically deploys the build to our staging environment. Then our engineers can test the change end-to-end with Postman using JSON requests. We also monitor exceptions in Sentry and metrics in Datadog before we manually deploy the change to production.
Results
The microservices architecture has allowed us to iterate fast while achieving high availability and scalability.
As a team with modest infrastructure experience, we’ve leveraged managed services provided by AWS when possible, and built our own infrastructure when necessary.
Fun Facts
We’ve built 9 microservices with 5 engineers.
Our engineers can bootstrap a new microservice and deploy it to Kubernetes in 30 minutes with our Java service template.
After a change is accepted, it can be deployed to the staging environment in 10 minutes.
We haven’t had any outages caused by microservices infrastructure.
We can easily scale a service by adding more Kubernetes pods to the service.
With our microservices infrastructure, we easily separated production and staging environments in 2 weeks.
Final Thoughts
Looking back, adopting Java monorepo could have saved us time for managing dependencies, logging and configurations. We will explore migrating to a moneo repo and write follow up blog posts to further discuss proto registry, authentication, metrics and monitoring in the future. We are launching our product soon — if you are excited about building microservices at Cardless, please take a look at our open positions!
Join our team
We're looking for curious, driven, entrepreneurs to help us build the future of credit cards and loyalty.
Yifu Diao
Software Engineer
Engineering
Building Microservices from Scratch
We’re Cardless. We help brands launch credit cards for their most important customers. A bit more on us and our first brand partner, the Cleveland Cavaliers NBA team, here.
Monolith vs. Microservices
Building a credit card company from the ground up is a hefty task! We started investigating requirements in March 2020. By then, we knew consistency, availability, security and compliance would be crucial to the success of our systems.
The first decision we faced was whether to build a monolith or microservices.
While monolith can be built with a simple infrastructure and offer unified logging and configuration, we knew we would soon hit bottlenecks.
Microservices, on the other hand, have been adopted by practically all of our peer tech companies. A few members of our team formerly worked at companies that decided to transition from monolith to microservices, investing significant time and resources into the transition.
We knew it would take several quarters to build the product, so starting with microservices was the clear choice to save us the migration down the line. Benefits include:
Decoupling — each service is free to choose its own technologies such as programming language and database.
Parallel development — each service can be developed and deployed independently, accelerating development speed and minimizing the blast radius if one deployment goes wrong.
Clarity of ownership — ownership of each service is well-defined, as is the set of things owned by each individual and team — avoiding the all-too-common situation of fuzzy ownership of a large shared monolith codebase.
The latest and greatest — building microservices from scratch means we can leverage the latest and best technologies such as gRPC, Kubernetes and Envoy.
gRPC and Proto Registry
RPC vs REST API
With a microservices architecture, we need to have an API framework for inter service communications. Compared to REST API, RPC offers several benefits:
Clear interface definition for input, output and error handling.
Automatically generated data access classes that are easier to use programmatically.
Compact, schematized binary formats used in RPC offer significant efficiencies over JSON data payloads.
So, we chose RPC.
gRPC vs Thrift
We then had to decide between the two popular RPC frameworks: gRPC and Apache Thrift. Our team had experience with Thrift, but after some investigation we found gRPC has some clear advantages:
Well maintained. gRPC is backed by Google. While Thrift was open sourced by Facebook, they have since forked with fbthrift and stopped development on Apache Thrift.
Better documentation. gRPC and Protocol Buffers has much better documentation than Apache Thrift.
Officially supported clients. gRPC has official support for all major languages, while Apache thrift only offers community implementation
Built with HTTP/2. Enables multiplexing HTTP/2 transport and bi-directional streaming.
Once again, we had a clear frontrunner.
Proto Registry
Once we had chosen to use gRPC, how did we organize the proto files? Each of our gRPC services had their own repository, and initially we had each service defining its proto file in the same repository.
For service A to call service B, we needed to manually copy the proto file of service B into service A to generate the client code.
We quickly realized that this approach wouldn’t scale and is also prone to error. So we built a proto registry that has all the proto files in one repository.
The proto registry publishes generated code as Java packages to Github Packages whenever a new change is merged to the master branch. As a result, whenever we need to make proto changes, we make them in the proto registry repository, merge it and upgrade the service to use the latest proto Java library.
This approach has worked very well for us so far, and has had the added benefit of enabling us to share some common proto files across services.
Microservices Infrastructure
Hosting: ECS vs Kubernetes -> Amazon EKS
The first infrastructure decision we faced was where to host the microservices.
We first experimented with Amazon ECS, and found it very easy to onboard. We then evaluated Kubernetes — we liked that it doesn’t require vendor lock in and has a much better ecosystem than Amazon ECS.
As a result, we decided to build a Kubernetes cluster with Amazon EKS, a managed Kubernetes service.
We used EC2 instead of AWS Fargate since Kubernetes already offers the auto scaling feature provided by Fargate. We placed all the nodes in the private subnet so that only the Amazon API Gateway could access them. With the Kubernetes cluster up and running, we configured each microservice to have its own Kubernetes deployment and service.
Service Mesh: Envoy + AWS App Mesh
Now that our services were running in Kubernetes and serving gRPC requests, how did they talk to each other?
We were surprised to find that Kubernetes’s default load balancing doesn’t work out of the box with gRPC. This is because gRPC was built on HTTP/2, which breaks the standard connection-level load balancing, including what’s provided by Kubernetes (more in this Kubernetes blog post).
We found there were a few service mesh solutions that add gRPC load balancing to Kubernetes clusters, namely Envoy, Istio and Linkerd.
After some investigation, we decided to use Envoy, which is both popular and provided as a managed service in AWS App Mesh. We configured AWS App Mesh as a Kubernetes CRD, so that Envoy sidecars are automatically injected into Kubernetes pods.
Envoy as the Front Proxy
Once our services were talking to each other through gRPC, how would our mobile and web clients talk to our services?
Our first thought was to just use gRPC, however we also needed Amazon API Gateway for authentication and VeryGoodSecurity for tokenization, and neither of them supports gRPC.
We did some investigation and found both Envoy and gRPC Gateway could act as a front proxy to transcode JSON requests to gRPC. We decided to use Envoy, since we were already using it as a sidecar to our services. We deployed the front proxy to Kubernetes and used an internal Network Load Balancer (NLB) to, well, balance loads.
The following is a simplified version of our Envoy front proxy configuration, which connects to the Users service in our service mesh:
static_resources:
listeners:
- name: restlistener
address:
socket_address:
address: 0.0.0.0
port_value: 80
filter_chains:
- filters:
- name: envoy.http_connection_manager
config:
stat_prefix: grpc_json
codec_type: AUTO
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains:
- '*'
routes:
- match:
prefix: /users
route:
cluster: users-service
timeout:
seconds: 60
http_filters:
- name: envoy.grpc_json_transcoder
config:
match_incoming_request_route: true
proto_descriptor: /proto/endpoints.pb
services:
- cardless.proto.api.users.UsersService
convert_grpc_status: true
print_options:
add_whitespace: true
always_print_primitive_fields: true
always_print_enums_as_ints: false
preserve_proto_field_names: false
- name: envoy.router
clusters:
- name: users-service
connect_timeout: 1.25s
type: logical_dns
lb_policy: round_robin
dns_lookup_family: V4_ONLY
http2_protocol_options: {}
hosts:
- socket_address:
address: users.svc.local
port_value: 10001The eagle-eyed among you may have noticed the file /proto/endpoints.pb referenced in the front proxy configuration. This file contains the descriptor sets generated from our proto registry.
Each microservice will expose their APIs by adding a HTTP annotation like this:
import "google/api/annotations.proto";
service UsersService {
rpc GetUser (GetUserRequest) returns (GetUserResponse){
option (google.api.http) = {
post: "/users/get-user"
And then we generate the endpoints.pb in the proto registry with this command:
protoc \
--include_imports \
--include_source_info \
--proto_path=./googleapis \
--proto_path=./cardless/proto \
--descriptor_set_out=descriptors/endpoints.pb \
./cardless/proto/users/api/users.protoAmazon API Gateway and Authentication
Our Envoy front proxy could transcode JSON requests to gRPC, but we still needed an API gateway to handle authentication and CORS and act as the web application firewall.
For enhanced peace of mind, we think it’s particularly important to let the API gateway authenticate all requests, instead of relying on each microservice to do so.
With this requirement, we found Amazon API Gateway’s support for OAuth with JWT Authorizers very attractive. The JWT Authorizer validates the access token in the authorization header of each request, making sure all the requests that reach our Envoy front proxy have been authenticated.
For issuing access tokens, we evaluated Amazon Cognito and Auth0, but decided to implement our own OAuth server with Spring Security since auth is at the core of our system and neither Amazon Cognito nor Auth0 provides sufficient flexibility.The OAuth server issues access tokens and refresh tokens after users authenticate with username and password, it also handles 2FA and password reset.
Developer Experience
We adopted a microservices architecture to enable engineers to iterate fast, but microservices also came with some overhead. So what could we do to provide a good developer experience?
Engineering Design Template
After a high level design exercise, we had a rough idea which microservices needed to be built. We wrote an engineering design template that guides engineers to think about alternatives (internal and external), architecture, API, database schema, infrastructure choices and security when proposing a new microservice.
After the engineer finishes the design document, we have a design review meeting and reach a consensus before we start building.
Java as Our Default Backend Language
One of the guidelines in the engineering design template is to use Java as the backend language unless there are strong reasons not to. Java’s static typing, high performance and rich ecosystem makes it a great choice as a backend language. But those aren’t the only reasons we make this recommendation.
By having a single backend language, engineers can work on multiple services easily. It also simplifies our effort to maintain shared libraries and service bootstrap templates.
Testing and Monitoring
For new changes, our engineers use Bloom RPC to test the updated gRPC endpoint locally. After the change is merged into the master branch, our CircleCI pipeline automatically deploys the build to our staging environment. Then our engineers can test the change end-to-end with Postman using JSON requests. We also monitor exceptions in Sentry and metrics in Datadog before we manually deploy the change to production.
Results
The microservices architecture has allowed us to iterate fast while achieving high availability and scalability.
As a team with modest infrastructure experience, we’ve leveraged managed services provided by AWS when possible, and built our own infrastructure when necessary.
Fun Facts
We’ve built 9 microservices with 5 engineers.
Our engineers can bootstrap a new microservice and deploy it to Kubernetes in 30 minutes with our Java service template.
After a change is accepted, it can be deployed to the staging environment in 10 minutes.
We haven’t had any outages caused by microservices infrastructure.
We can easily scale a service by adding more Kubernetes pods to the service.
With our microservices infrastructure, we easily separated production and staging environments in 2 weeks.
Final Thoughts
Looking back, adopting Java monorepo could have saved us time for managing dependencies, logging and configurations. We will explore migrating to a moneo repo and write follow up blog posts to further discuss proto registry, authentication, metrics and monitoring in the future. We are launching our product soon — if you are excited about building microservices at Cardless, please take a look at our open positions!
Join our team
We're looking for curious, driven, entrepreneurs to help us build the future of credit cards and loyalty.
Yifu Diao
Software Engineer
Engineering
Building Microservices from Scratch
We’re Cardless. We help brands launch credit cards for their most important customers. A bit more on us and our first brand partner, the Cleveland Cavaliers NBA team, here.
Monolith vs. Microservices
Building a credit card company from the ground up is a hefty task! We started investigating requirements in March 2020. By then, we knew consistency, availability, security and compliance would be crucial to the success of our systems.
The first decision we faced was whether to build a monolith or microservices.
While monolith can be built with a simple infrastructure and offer unified logging and configuration, we knew we would soon hit bottlenecks.
Microservices, on the other hand, have been adopted by practically all of our peer tech companies. A few members of our team formerly worked at companies that decided to transition from monolith to microservices, investing significant time and resources into the transition.
We knew it would take several quarters to build the product, so starting with microservices was the clear choice to save us the migration down the line. Benefits include:
Decoupling — each service is free to choose its own technologies such as programming language and database.
Parallel development — each service can be developed and deployed independently, accelerating development speed and minimizing the blast radius if one deployment goes wrong.
Clarity of ownership — ownership of each service is well-defined, as is the set of things owned by each individual and team — avoiding the all-too-common situation of fuzzy ownership of a large shared monolith codebase.
The latest and greatest — building microservices from scratch means we can leverage the latest and best technologies such as gRPC, Kubernetes and Envoy.
gRPC and Proto Registry
RPC vs REST API
With a microservices architecture, we need to have an API framework for inter service communications. Compared to REST API, RPC offers several benefits:
Clear interface definition for input, output and error handling.
Automatically generated data access classes that are easier to use programmatically.
Compact, schematized binary formats used in RPC offer significant efficiencies over JSON data payloads.
So, we chose RPC.
gRPC vs Thrift
We then had to decide between the two popular RPC frameworks: gRPC and Apache Thrift. Our team had experience with Thrift, but after some investigation we found gRPC has some clear advantages:
Well maintained. gRPC is backed by Google. While Thrift was open sourced by Facebook, they have since forked with fbthrift and stopped development on Apache Thrift.
Better documentation. gRPC and Protocol Buffers has much better documentation than Apache Thrift.
Officially supported clients. gRPC has official support for all major languages, while Apache thrift only offers community implementation
Built with HTTP/2. Enables multiplexing HTTP/2 transport and bi-directional streaming.
Once again, we had a clear frontrunner.
Proto Registry
Once we had chosen to use gRPC, how did we organize the proto files? Each of our gRPC services had their own repository, and initially we had each service defining its proto file in the same repository.
For service A to call service B, we needed to manually copy the proto file of service B into service A to generate the client code.
We quickly realized that this approach wouldn’t scale and is also prone to error. So we built a proto registry that has all the proto files in one repository.
The proto registry publishes generated code as Java packages to Github Packages whenever a new change is merged to the master branch. As a result, whenever we need to make proto changes, we make them in the proto registry repository, merge it and upgrade the service to use the latest proto Java library.
This approach has worked very well for us so far, and has had the added benefit of enabling us to share some common proto files across services.
Microservices Infrastructure
Hosting: ECS vs Kubernetes -> Amazon EKS
The first infrastructure decision we faced was where to host the microservices.
We first experimented with Amazon ECS, and found it very easy to onboard. We then evaluated Kubernetes — we liked that it doesn’t require vendor lock in and has a much better ecosystem than Amazon ECS.
As a result, we decided to build a Kubernetes cluster with Amazon EKS, a managed Kubernetes service.
We used EC2 instead of AWS Fargate since Kubernetes already offers the auto scaling feature provided by Fargate. We placed all the nodes in the private subnet so that only the Amazon API Gateway could access them. With the Kubernetes cluster up and running, we configured each microservice to have its own Kubernetes deployment and service.
Service Mesh: Envoy + AWS App Mesh
Now that our services were running in Kubernetes and serving gRPC requests, how did they talk to each other?
We were surprised to find that Kubernetes’s default load balancing doesn’t work out of the box with gRPC. This is because gRPC was built on HTTP/2, which breaks the standard connection-level load balancing, including what’s provided by Kubernetes (more in this Kubernetes blog post).
We found there were a few service mesh solutions that add gRPC load balancing to Kubernetes clusters, namely Envoy, Istio and Linkerd.
After some investigation, we decided to use Envoy, which is both popular and provided as a managed service in AWS App Mesh. We configured AWS App Mesh as a Kubernetes CRD, so that Envoy sidecars are automatically injected into Kubernetes pods.
Envoy as the Front Proxy
Once our services were talking to each other through gRPC, how would our mobile and web clients talk to our services?
Our first thought was to just use gRPC, however we also needed Amazon API Gateway for authentication and VeryGoodSecurity for tokenization, and neither of them supports gRPC.
We did some investigation and found both Envoy and gRPC Gateway could act as a front proxy to transcode JSON requests to gRPC. We decided to use Envoy, since we were already using it as a sidecar to our services. We deployed the front proxy to Kubernetes and used an internal Network Load Balancer (NLB) to, well, balance loads.
The following is a simplified version of our Envoy front proxy configuration, which connects to the Users service in our service mesh:
static_resources:
listeners:
- name: restlistener
address:
socket_address:
address: 0.0.0.0
port_value: 80
filter_chains:
- filters:
- name: envoy.http_connection_manager
config:
stat_prefix: grpc_json
codec_type: AUTO
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains:
- '*'
routes:
- match:
prefix: /users
route:
cluster: users-service
timeout:
seconds: 60
http_filters:
- name: envoy.grpc_json_transcoder
config:
match_incoming_request_route: true
proto_descriptor: /proto/endpoints.pb
services:
- cardless.proto.api.users.UsersService
convert_grpc_status: true
print_options:
add_whitespace: true
always_print_primitive_fields: true
always_print_enums_as_ints: false
preserve_proto_field_names: false
- name: envoy.router
clusters:
- name: users-service
connect_timeout: 1.25s
type: logical_dns
lb_policy: round_robin
dns_lookup_family: V4_ONLY
http2_protocol_options: {}
hosts:
- socket_address:
address: users.svc.local
port_value: 10001The eagle-eyed among you may have noticed the file /proto/endpoints.pb referenced in the front proxy configuration. This file contains the descriptor sets generated from our proto registry.
Each microservice will expose their APIs by adding a HTTP annotation like this:
import "google/api/annotations.proto";
service UsersService {
rpc GetUser (GetUserRequest) returns (GetUserResponse){
option (google.api.http) = {
post: "/users/get-user"
And then we generate the endpoints.pb in the proto registry with this command:
protoc \
--include_imports \
--include_source_info \
--proto_path=./googleapis \
--proto_path=./cardless/proto \
--descriptor_set_out=descriptors/endpoints.pb \
./cardless/proto/users/api/users.protoAmazon API Gateway and Authentication
Our Envoy front proxy could transcode JSON requests to gRPC, but we still needed an API gateway to handle authentication and CORS and act as the web application firewall.
For enhanced peace of mind, we think it’s particularly important to let the API gateway authenticate all requests, instead of relying on each microservice to do so.
With this requirement, we found Amazon API Gateway’s support for OAuth with JWT Authorizers very attractive. The JWT Authorizer validates the access token in the authorization header of each request, making sure all the requests that reach our Envoy front proxy have been authenticated.
For issuing access tokens, we evaluated Amazon Cognito and Auth0, but decided to implement our own OAuth server with Spring Security since auth is at the core of our system and neither Amazon Cognito nor Auth0 provides sufficient flexibility.The OAuth server issues access tokens and refresh tokens after users authenticate with username and password, it also handles 2FA and password reset.
Developer Experience
We adopted a microservices architecture to enable engineers to iterate fast, but microservices also came with some overhead. So what could we do to provide a good developer experience?
Engineering Design Template
After a high level design exercise, we had a rough idea which microservices needed to be built. We wrote an engineering design template that guides engineers to think about alternatives (internal and external), architecture, API, database schema, infrastructure choices and security when proposing a new microservice.
After the engineer finishes the design document, we have a design review meeting and reach a consensus before we start building.
Java as Our Default Backend Language
One of the guidelines in the engineering design template is to use Java as the backend language unless there are strong reasons not to. Java’s static typing, high performance and rich ecosystem makes it a great choice as a backend language. But those aren’t the only reasons we make this recommendation.
By having a single backend language, engineers can work on multiple services easily. It also simplifies our effort to maintain shared libraries and service bootstrap templates.
Testing and Monitoring
For new changes, our engineers use Bloom RPC to test the updated gRPC endpoint locally. After the change is merged into the master branch, our CircleCI pipeline automatically deploys the build to our staging environment. Then our engineers can test the change end-to-end with Postman using JSON requests. We also monitor exceptions in Sentry and metrics in Datadog before we manually deploy the change to production.
Results
The microservices architecture has allowed us to iterate fast while achieving high availability and scalability.
As a team with modest infrastructure experience, we’ve leveraged managed services provided by AWS when possible, and built our own infrastructure when necessary.
Fun Facts
We’ve built 9 microservices with 5 engineers.
Our engineers can bootstrap a new microservice and deploy it to Kubernetes in 30 minutes with our Java service template.
After a change is accepted, it can be deployed to the staging environment in 10 minutes.
We haven’t had any outages caused by microservices infrastructure.
We can easily scale a service by adding more Kubernetes pods to the service.
With our microservices infrastructure, we easily separated production and staging environments in 2 weeks.
Final Thoughts
Looking back, adopting Java monorepo could have saved us time for managing dependencies, logging and configurations. We will explore migrating to a moneo repo and write follow up blog posts to further discuss proto registry, authentication, metrics and monitoring in the future. We are launching our product soon — if you are excited about building microservices at Cardless, please take a look at our open positions!
Join our team
We're looking for curious, driven, entrepreneurs to help us build the future of credit cards and loyalty.
Engineering
Welcome to the first blog post from Cardless Engineering. Come join us!
Yifu Diao
Software Engineer
Join our team
We're looking for curious, driven, entrepreneurs to help us build the future of credit cards and loyalty.